She Designs Shoes
When I introduce Sara Jaramillo to people that And Them works with, I always wants to say, ‘My Sara’ because everyone should have their own ‘Sara’. I believe ‘My Sara’ evolved from our days on Yeezy…
独家优惠奖金 100% 高达 1 BTC + 180 免费旋转
Diabetic Retinopathy Detection
Diabetic retinopathy is the most common form of diabetic eye disease and usually affects people who have diabetes for a significant number of years. The risk of diabetic eye is for aged people especially working persons in rural and slum areas.
It increases with age as well as with less well-controlled blood sugar and blood pressure level and occurs when the damaged blood vessels leak blood and other fluids into your retina, causing swelling and blurry vision. The blood vessels can become blocked, scar tissue can develop, and retinal detachment can eventually occur.
Retinopathy can affect all diabetics and becomes particularly dangerous by increasing the risk of blindness if it is left untreated. The condition is easiest to treat in the early stages, which is why it is important to undergo routine eye exams before it becomes too late for treatment.
They want us to build a system where it takes the retinal image of a patient and tells us the severity of diabetic retinopathy.
We have scanned images, then why can’t we use trained doctors to diagnosis the disease instead of using the black box system? Is there a need for automation here? Yes!, There are a couple of advantages here like below.
Chapter-1: Data Extraction / Importing the Data and Setup
Chapter-2: Exploratory Data Analysis
Chapter-3 : Evaluation Metrics
Chapter-4: A solution through Deep Learning - Concept of Convolutional Neural Networks
Chapter-5: Ensembles
Chapter-6: Model Interpretability - Working on the Black box model.
Chapter-7: Conclusions
Source Of Data:
It will give aptos2019-blindness-detection.zip file in 2–3 minutes. However, we can extract all the below files by unzipping that file using the following command in 4–5 minutes
The competition has given 5 files occupying 9.52 GB of space.
Observations:
The clinicians have rated each image for the severity of diabetic retinopathy on a scale of 0 to 4. It is a multi-class problem with 5 target classes
Observations:
Image Analysis:
Splitting the Dataset:
After splitting the data we need to store the files permanently so that there will be no problem of data leakage in future training.
Each row depicts the severity level of the disease retinopathy.
There are four major problems in our dataset which will make our model difficult to spot the identities.
Most of the training images are type-I and type-III, test images with type-III.
Steps involved in Image Preprocessing:
After applying image preprocessing on training dataset:
Image to vector conversion:
Everything is perfect. Now we are ready for model training :)
There are five outcomes in our model i.e., [0,1,2,3,4]. Now we can transform these labels either using
For example, if the target label is 2 then it will be encoded as [0,0,1,0,0]
For example, if the target label is 2 then it will be encoded as [1,1,1,0,0] which means the sample with class-2 also belongs to the classes before it (0,1)
The competition has given a weighted kappa score as an evaluation metric. Let’s just see what it is meant for.
Quadratic Weighted Cohen’s kappa score:
Why using a weighted kappa metric?
There are a lot of metrics to compare the results like confusion matrix, accuracy, recall, precision, etc.., Then why to use a new metric?
Since the data set is highly imbalanced adding class weight can make it balanced by adding weights to each of the classes.
The class with more weight means they are less in samples. Similarly, the class with less weight means they are more in samples.
Custom Callbacks:
Here we will modify the callback class in TensorFlow in order to print the kappa metric on each epoch on validation data.
Convolutional Neural Networks(CNN):
Machine Learning research has focused extensively on object detection problems over time. But various things make it hard to recognize objects like segmentation, lighting, Deformation, etc..,
First I started with a baseline model to estimate the final score and to make necessary changes in model training. Here I used simple
Performance Metrics on Validation dataset:
Now let’s try model training with Alexnet architecture.
Highlights of the paper:
After running the model for 30 epochs I got a kappa score of 0.7758 on validation data which is better than the baseline model.
Performance Metrics on Validation dataset:
We hardly have ~3k images on training and ~500 images for validation. Any deep learning model with a small dataset will prone to overfit easily which is not there in baseline and alexnet but still, it’s good to have a large set of data.
By augmentation, we can increase the size of our dataset at runtime without actually storing them in our system. I used the following four augmentation techniques which will increase our dataset by 4 times.
Transfer learning focuses on storing knowledge gained while solving one problem and applying it to a different but related problem.
I am using pre-trained models that are trained on the imagenet dataset.
All the pretrained model architectures are extended with the following three layers.
Visual Geometry Group (VGG):
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.8931 on validation data.
Performance Metrics on Validation dataset:
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9128 on validation data.
Performance Metrics on Validation dataset:
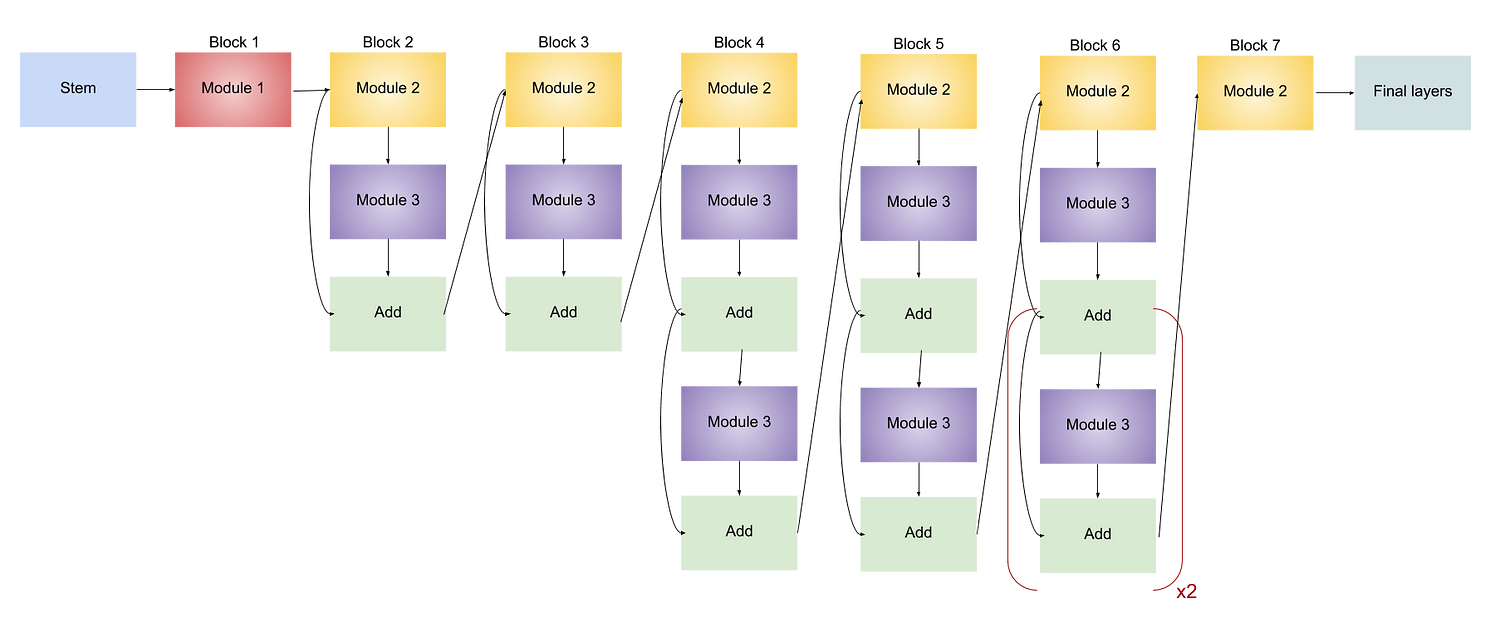
DenseNet Architecture:
DenseNet with 121 layers:
=> 5+(6+12+24+16)*2 = 121
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.923 on validation data.
Performance Metrics on Validation dataset:
Residual Networks:
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9091 on validation data.
Performance Metrics on Validation dataset:
{kind=link}
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9146 on validation data.
Performance Metrics on Validation dataset:
Inception Networks:
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9014 on validation data.
Performance Metrics on Validation dataset:
Efficient Net Networks:
{kind=link}
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9144 on validation data.
Performance Metrics on Validation dataset:
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9199 on validation data.
Performance Metrics on Validation dataset:
{kind=link}
Tensorboard Visualization:
After training the model for 30 epochs I got a kappa score of 0.9193 on validation data.
Performance Metrics on Validation dataset:
Xception Architecture:
Xception is an efficient architecture that relies on two main points :
Tensorboard visualization:
After training the model for 30 epochs I got a kappa score of 0.9161 on validation data.
Performance Metrics on Validation dataset:
All the predictions made by pretrained models are stored onto a .CSV file separately for train, validation, and test datasets.
Ensemble methods is a machine learning technique that combines several base models to produce one optimal predictive model.
There are two major techniques for applying ensemble models
Taking N model predictions and taking the max count of labels as final class predictions.
For example [1,0,0,1,1,1,2] these are N model predictions then the final class will be predicted as 1 since 4 models predicted as 1, 2 models as 0, and 1 model as 2.
Hence the class prediction = max count of labels i.e.,1
The validation kappa score on ensembles is 0.9314. Which is the best score among all the models.
Performance Metrics on Validation dataset:
Overall Results:
“Illusions are always better than stupid conclusions”
Where the cyan color indicates the higher activations in predicting the class (ball here).
Plotting model interpretability over each class samples. Here Each row depicts the severity of the disease.
Some of the Predictions of class-0 (No DR) from validation data:
Observations:
Some of the Predictions of Class-1 (Mild) from validation data:
Observations:
Some of the predictions of Class-2 (Moderate) from validation data:
Observations:
Some of the Predictions of class-3 (Severe) from validation data:
Observations:
Some of the Predictions of class-4(ProliferativeDR) from validation data:
Observations:
Error rate = False predictions on that class / total predictions on that class
Count of Predictions which are less than the true predictions:
Here 10 samples actually belong to class-1 but predicted as class-0. These 10 cases are the most important to examine because these patients actually have retinopathy(mild stage) but are predicted as having No retinopathy.
Plotting those 10 Samples:
The final solution to our problem statement:
About Model Training:
Future Work:
References:
As an aspirant of becoming a Data Scientist brings me here. This includes my final work for this case study. Thank you for reading my article.
You can also read to my other articles and case studies here.
I hope you have learned something out of this. There is no end for learning in this area so Happy learning!! The signing of bye :)
Related posts:
Capturing Hummingbirds with Deep Learning
Hummingbirds are neat to look at, so it’s not surprising that hummingbird feeders are popular garden additions. If you have the time to sit around and wait, you can watch them hover pleasingly around…
Setting an Aspirational Hourly Rate
The key to unlocking the power of automation is adopting the right mindset. One way to do that — and something that’s helped me is setting an aspirational hourly rate to reflect my income goals. And…
Buscadero
Introducing Buscaderos by Dero Desperados, our exclusive ultra legendary rank. Available solely as NFAs in the dReams marketplace, Buscaderos is a highly sought-after addition to the Dero Desperados…